Hermetic Word Frequency Counter | ||
Counts Frequencies of Different Words in a File | ||
Hermetic Word Frequency Counter | ||
Counts Frequencies of Different Words in a File | ||
This software runs on any version of Windows. It is fully-functional and not time-limited.
Donate via Stripe to download this software.
To open a file, click on the Input file button and navigate to the desired folder and file. After setting the operation parameters, click on the Count words button. Here is a typical screenshot, showing word counts for a 123.75 Kb text file, with common words ignored, upper/lower case distinguished, the words sorted by frequency, and the archaic words "hath" and "howbeit" ignored:
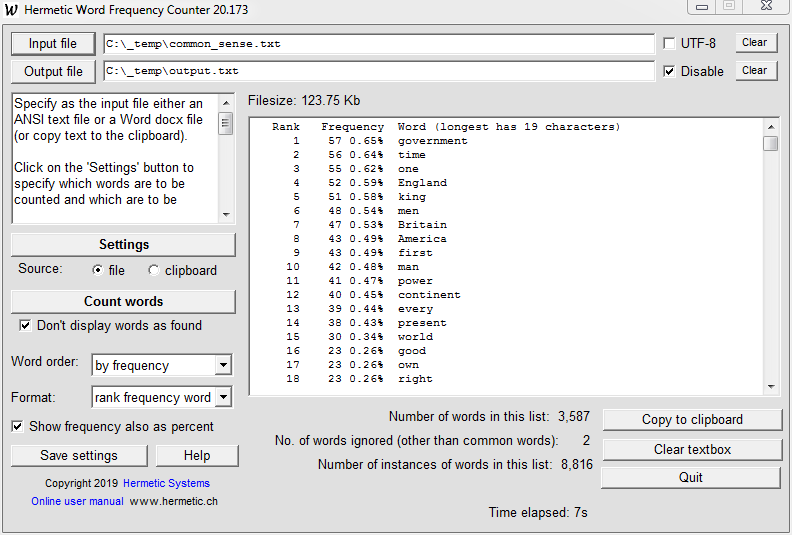
The "percentage" value is the ratio of the number of occurrences of a word divided by the total number of occurrences of all words shown in the list (not all words in the file) expressed as a percentage.
If the "Disable" box (on the same line as "Output file") is checked then output is to the text box only, not to a file.
Here is another screenshot, showing word counts for a 67.37 Kb MS Word docx file (the text itself, when unpacked, is 110.21 Kb), with common words ignored, upper/lower case not distinguished, and the words sorted alphabetically:
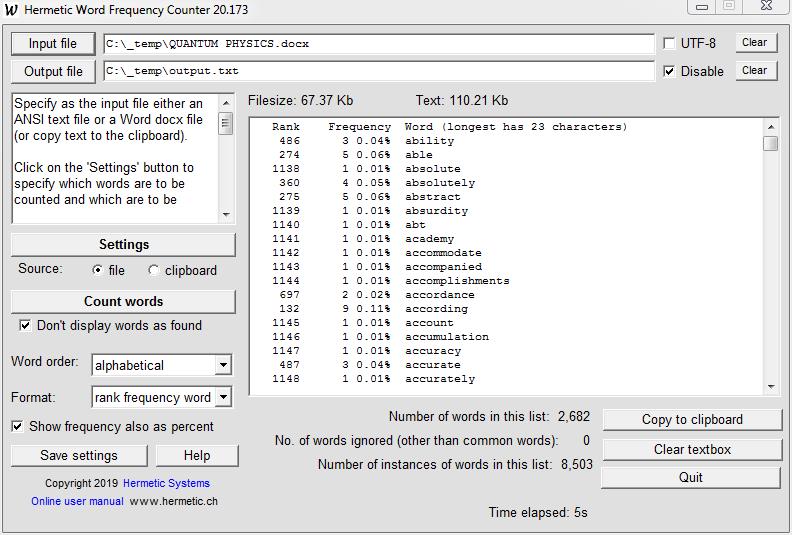
In both cases the process took less than ten seconds (with the Don't display words as found checkbox checked).
"Filesize" is the size of the docx file; "Text" is the size of the text within that file. The former is smaller than the latter because the text within the docx file is compressed.
Theoretically there is no limit on the size of an input file or the number of words in it, but in practice (due to processing time needed) there is a limit of about 10 Mb on text files (and text-like files such as XML and HTML files). There is also a limit of about 10 Mb on the amount of text in an MS Word docx file (though a docx file can be larger than this if it contains many images). For a docx file, only words in the body of the document are counted, not words in footnotes or endnotes.
| ANSI is the single-byte text encoding which is the default encoding on your PC. UTF-8 is a variable-byte-length encoding of Unicode characters, often used in HTML and XML files. |
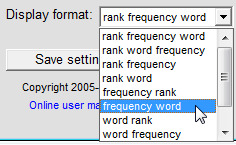 The 'rank' and 'frequency' values may each be included in, or excluded from, the displayed results.
The 'rank' and 'frequency' values may each be included in, or excluded from, the displayed results.
code,convert,converter,file,folder,html,software,source,windows
When processing HTML files, HTML tags such as "<center>" are skipped. When processing XML files all text within "<" and ">" is skipped. PHP files are processed as HTML files in which C-style comments are possible. When processing PHP files, text within "<?php" and "?>" is not skipped.
Hermetic Word Frequency Counter User Manual |